Che cos'è un Data Lakehouse?
Un Data Lakehouse è un'architettura dati che combina e unifica (in una singola piattaforma, generalmente su cloud) le architetture e le capacità di un data warehouse e quelle di un data lake. Questo tipo di configurazione consente di ridurre le ridondanze e di semplificare diversi aspetti del data management, dal design dell'architettura alla manutenzione, dall'ottimizzazione alla gestione dei dati.
Il futuro del mondo data passa per il Data Lakehouse?
Se ne parla molto tra i grandi player del settore, ma i settori produttivi hanno ancora qualche incertezza nel dirigersi verso l'adozione di queste soluzioni di convergenza. Il grande vantaggio è noto ed è principalmente costituito dal fatto che il dato è disponibile in minor tempo per il warehouse e i suoi utilizzi (report, dashboard, self-service, analytics, ecc.) in quanto non è necessario spostarlo da una piattaforma ad un'altra per poterlo analizzare.
Nondimeno, mentre l'architettura di un Data Lakehouse può essere molto utile per alcune aree, in altri casi non riesce a ridurre in modo considerevole il lavoro complessivo richiesto e, di conseguenza, i benefici che genera non sono all'altezza delle aspettative.
Quindi, se in generale l'adozione di un Data Lakehouse può portare dei benefici, vi sono anche alcune eccezioni. Per esempio, una singola piattaforma lakehouse è una classica architettura monolitica (che rinuncia alla ricchezza delle funzioni in cambio di una maggiore semplicità) e perciò è soggetta alle tipiche limitazioni di questo genere di piattaforme. Alcuni vendor sostengono che sia vantaggioso avere quella che loro definiscono una singola fonte di verità o un'unica copia dei dati, ma la separazione del data lake dal data warehouse offre una maggiore chiarezza nella governance e nell'allineamento dei modelli di consumo che si confonderebbero, invece, nel Lakehouse, complicando potenzialmente la governance e la qualità dei dati.
Rispetto alla maggior parte delle altre architetture, un lakehouse prevede un elenco più breve di fornitori (tipicamente, un fornitore anziché due o più), ma ciò non fa altro che aumentare il rischio di vendor lock-in. Nuovi supporti per Apache Iceberg e Delta Lake da parte di molte piattaforme potrebbero mitigare questo rischio.
Scegliere una piattaforma appropriata è la principale sfida da vincere per implementare con successo un Data Lakehouse, perché sono poche le piattaforme che riescono a gestire a livelli ottimali sia il lake che il warehouse. Per questo, in molti casi, è preferibile una soluzione alternativa, una terza via costituita dalla data virtualization.
La data virtualization, e più in generale la data integration, si sta facendo sempre più largo all’interno delle strategie di data engineering di moltissime aziende. La possibilità di unificare agilmente i dati provenienti da diverse fonti (tabelle, file, web, gestionali e molto altro) consente di semplificarne le attività di analisi con notevoli vantaggi. Miriade è Best South Europe & Middle East Partner di Denodo, stabilmente inserito come Leader del Magic Quadrant™ Gartner® per i Data Integration Tools, per questo ha un approccio aperto ad ogni tipo di soluzione che si adatti perfettamente alle esigenze dell'azienda, sia che si tratti di optare per un data lakehouse, sia che si tratti di perseguire una strategia di data integration.
Data Lakehouse nel dettaglio: come integra data lake e data warehouse?
Integrare un lake e un warehouse su due o più piattaforme produce ridondanza e complessità. Generalmente il dato è tipicamente ospitato nel lake trasportato al warehouse grazie a tecnologie di integrazione, e qui raffinato e caricato prima di essere reso disponibile alla produzione. In questo scenario la ridondanza aumenta la complessità e le operazioni di manutenzione delle piattaforme integrate, rallenta il delivery dei dati e la capacità del management di rispondere alle sfide, rende inoltre difficile l'ottimizzazione.
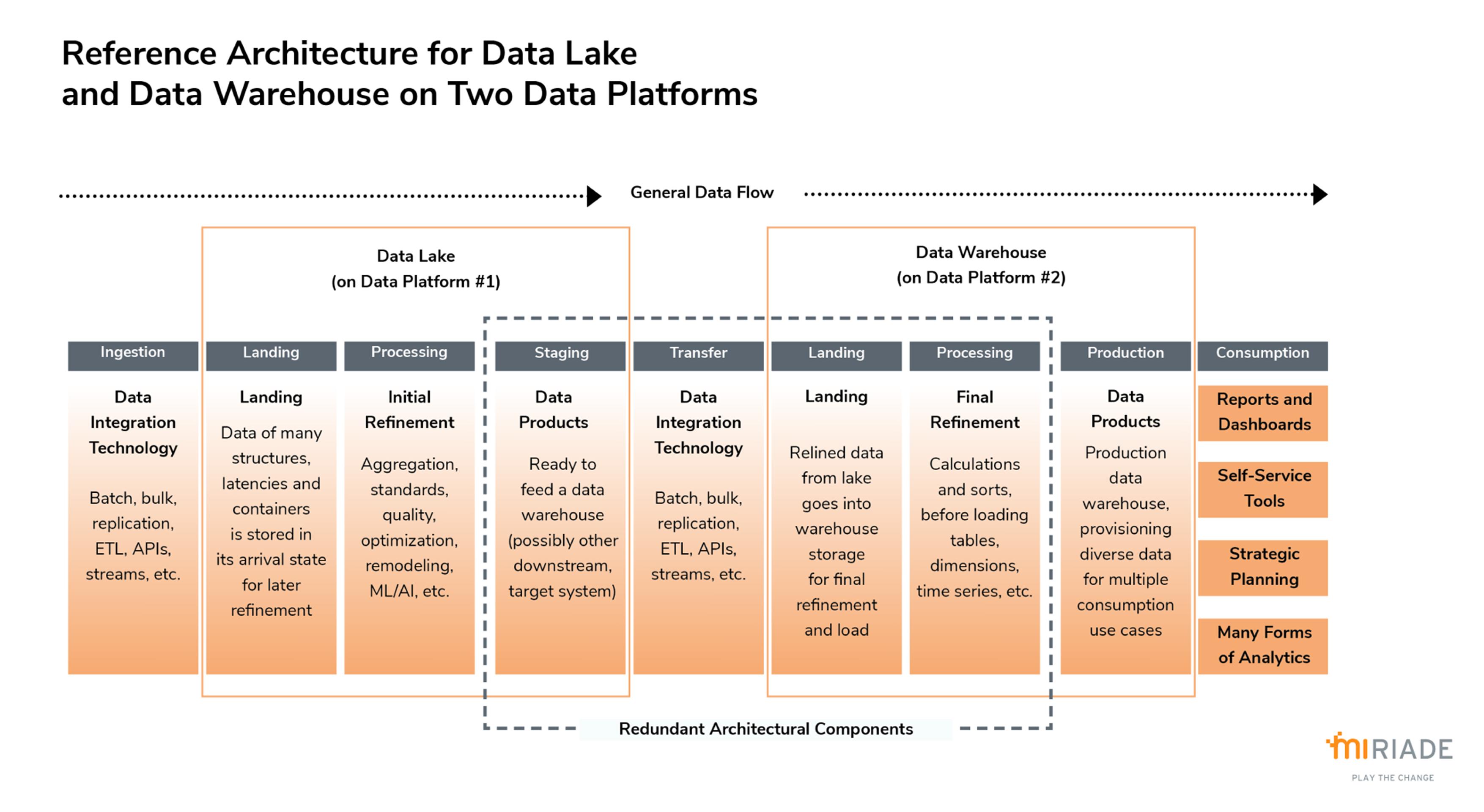
La principale prerogativa del data lakehouse è invece quella di ridure la ridondanza generata dall'integrazione lake-to-warehouse, collocando sia il lake che il warehouse in un'unica piattaforma (solitamente cloud-based). In tal modo si elimina la necessità di trasferire i dati e tutti i componenti dell'architettura preposti solo a questo scopo.
- Senza il trasferimento dei dati da piattaforma a piattaforma, il lake del lakehouse non necessità di aree destinate ad ospitare dati in uscita. Allo stesso tempo, non servono aree nel warehouse per accogliere dati in entrata.
- Si possono eliminare anche pipeline, estrazioni, trasformazioni e caricamenti (ETL) destinati al trasferimento dei dati, perché sul cloud si dispone di uno storage condiviso per tutti i dati e i loro usi.
- Tutti i dati possono essere consolidati in una singola area, sebbene quest'area possa essere organizzata in molteplici dataset e processi, in quanto un lakehouse deve supportare molti casi d'uso.
- È più semplice implementare e utilizzare la Data Observability (in particolare monitorare i costi, il data lineage, l'utilizzo dei dati e altri tipi di metadati).

Data Lakehouse: la sfida è scegliere la piattaforma più appropriata
Se da un lato il Data Lakehouse offre dei benefici, la sua architettura presenta dall'altro anche alcune sfide che data architect e data analytst devono affrontare. È indispensabile, dunque, capire cosa fa "abbastanza bene" il data lake, in modo da sfruttarlo in questi ambiti.
Ambito del data lake
La maggior parte dei data lake sono definiti tali, ma non hanno un design proprio del data lake. Sono invece delle piattaforme che, su un certo ambito, hanno un mix fatto di analisi (dal reporting al data science) e operations (marketing, supply chain, monitoraggio dei processi). Generalmente, i singoli lake sono disegnati con una struttura di data warehouse e ne supportano gli utilizzi relativi (reports e dashboards). Per questo si deve prestare attenzione che il design del lakehouse sia coerente alle esigenze del business e, in tal modo, definire attentamente l'ambito che deve avere il lake in relazione al lakehouse.
Data swamp
Anche nel caso di lakehuse, gli utenti devono proteggere il data lake dal rischio di diventare un data swamp - come dice il nome, un pantano in cui affondano datti di ogni sorta e in cui si butta di tutto. Per evitare che questo accada il lake deve essere ben gestito, i contenuti curati, i dati devono essere corredati di metadati e documentazione adeguata, inoltre le aree dove vengono archiviati i dati devono essere sapientemente organizzate in data zones, buckets, tenets, folders, etc.
DBMS selection
Un'altra sfida che data architect e data analyst devono affrontare è costituita dal fatto che il sistema di gestione del dato all'interno del data lake deve essere performante, sia per un uso di DWH che di data lake. Per fare un esempio, le piattaforme di data warehouse supportano numerosi e diversi workloads concomitanti, sia in batch che in streaming, e un numero elevato di utenti che ne fruiscono contemporaneamente, mentre la maggior parte delle piattaforme lake, invece, sono state disegnate per piccoli gruppi di utenti. Le piattaforme di data lake supportano i dati di varie tipologie, mentre la maggior parte delle piattaforme warehouse sono ottimizzate per caricare dati relazionali. Perciò quando si sceglie una piattaforma di data lakehouse, si deve prestare attenzione che sia in grado di soddisfare funzioni e ottimizzazioni di entrambe le istanze.
Ti è piaciuto quanto hai letto? Iscriviti a MISPECIAL, la nostra newsletter, per ricevere altri interessanti contenuti.
Iscriviti a MISPECIAL
