
L'adozione di Kubernetes come orchestratore standard - in particolare di soluzioni gestite come Amazon EKS - promette agilità e scalabilità. Tuttavia, senza una governance strategica delle risorse, l'automazione può generare un paradosso: un aumento dell'efficienza operativa accompagnato da un'escalation incontrollata dei costi. Questo documento analizza, attraverso un Case Study, una sfida comune ma critica: la sovrallocazione di risorse causata da sistemi di provisioning dinamico come Karpenter (karpenter.sh). Attraverso un caso di studio reale, si vedrà come un'analisi metodica, basata su dati raccolti con Prometheus e Grafana, e l'implementazione di policy come LimitRange, possano non solo correggere la rotta, ma trasformare il cluster in un'infrastruttura altamente ottimizzata, riducendo gli sprechi e massimizzando il ritorno sull'investimento cloud.
Inizialmente, la gestione del nostro cluster EKS presentava delle sfide significative. Uno dei problemi principali era l'incapacità di schedulare nuovi pod a causa di un dimensionamento statico e manuale dei nodi, che raggiungevano rapidamente la saturazione. Questo approccio, seppur semplice, si rivelava inadeguato a gestire i picchi di domanda o le variazioni del carico di lavoro, portando a inefficienze e blocchi operativi quando le risorse disponibili non erano sufficienti per le nuove istanze applicative.
Per superare questa limitazione, abbiamo implementato Karpenter, un provisioner di nodi dinamico, con l'obiettivo di allocare risorse just-in-time. L'introduzione di Karpenter ha effettivamente risolto il problema della schedulazione dei pod, garantendo che ci fossero sempre nodi disponibili quando richiesto dalle applicazioni. La sua capacità di reagire rapidamente alle esigenze del cluster ha migliorato notevolmente la reattività del sistema e la disponibilità delle nostre applicazioni.
Tuttavia, l'adozione di Karpenter ha inavvertitamente introdotto una nuova problematica: un'eccessiva allocazione di nodi. Abbiamo notato che Karpenter tendeva a creare un numero elevato di nodi che, una volta terminato il picco di richiesta, rimanevano spesso inutilizzati o sottoutilizzati". (Introduce il concetto di sottoutilizzo, più corretto tecnicamente. Questo era particolarmente evidente in scenari dove le applicazioni passavano lunghi periodi in stato di "idle" (inattive), consumando poche o nessuna risorsa, ma occupando comunque nodi interi che potevano essere spenti o riutilizzati.
Questa sovrallocazione di risorse ha avuto un impatto diretto sui costi operativi e sull'efficienza complessiva del nostro ambiente EKS. Sebbene la scalabilità fosse garantita, lo spreco di risorse dovuto ai nodi inattivi ha reso necessario un ripensamento delle strategie di gestione e ottimizzazione dei costi all'interno del cluster.
Contesto
L'ambiente oggetto di analisi è un cluster Kubernetes gestito ospitato su AWS (EKS). Inizialmente, il cluster è stato configurato con una control plane gestita e un nodegroup iniziale di 3 nodi di taglia media (c5a.xlarge, 4 vCPU e 8GB di RAM). Con l'aumento degli applicativi ospitati e, di conseguenza, delle risorse necessarie, il nodegroup veniva esteso manualmente per far fronte alle crescenti esigenze. Successivamente, è stato implementato Karpenter per automatizzare il provisioning dinamico dei nodi, garantendo che i workload non rimanessero in attesa di schedulazione a causa della mancanza di risorse. Purtroppo l’introduzione di sistemi automatici di scaling con limiti particolarmente larghi non aiutano a contenere la quantità di risorse utilizzate e di conseguenza a mantenere facilmente i costi sotto controllo. Se non si sorveglia attentamente e non si interviene con dei correttivi, diventa difficile contenere la spesa.
Il problema
Come detto in precedenza, l’introduzione di un sistema di scaling just-in-time come Karpenter ha complicato di molto la gestione dei costi. Per maggiore chiarezza, è opportuno fare un passo indietro per illustrare il funzionamento di Karpenter e individuare la ragione dell'incremento dei costi.
Quando viene richiesta la messa in esecuzione di un nuovo pod in un cluster Kubernetes, il nuovo pod si trova in uno stato di pending. La permanenza in questo stato è solitamente breve. In un cluster in condizioni ottimali (“healthy”), lo scheduler identifica rapidamente dove eseguire il pod, che passa così allo stato successivo di “Running”.
Esistono delle situazioni però in cui questo non è possibile, poiché i requisiti posti dal pod non sono soddisfacibili e di conseguenza permane quindi nello stato “Pending”. I requisiti possono essere di vario tipo, come l’accesso alle risorse (disco, o device speciali), regole di antiaffinity e necessità di una quantità di risorse minime per l’esecuzione.
Quest’ultime sono denominate “Requests” e sono, assieme a “Limits”, le definizioni di vCPU/RAM che sono necessarie (requests) o massime (limits) a disposizione del pod.
Quando un pod ha una quantità di “requests” definite, lo scheduler deve trovare una macchina dove queste sono presenti. Il modo con cui vengono verificata la disponibilità è attraverso la somma delle definizioni di “requests” di tutti i pod in esecuzione. Per esempio, si consideri un nodo da 4 vCPU e 8 GB di RAM su cui sono in esecuzione 10 pod, 8 dei quali hanno una request definita di 0,25 vCPU.. Lo scheduler valuta, verifica che sono quindi riservate in totale 2 vCPU (8 x 0,25) e che sono disponibili altre 2 vCPU. Nel caso il pod da schedulare abbia una request di cpu minore o uguale a 2, troverà spazio per l’esecuzione, altrimenti cercherà altrove. Nel caso nessun nodo sia disponibile, resterà in “Pending”.
In questa situazione quindi interviene Karpenter, che trovando un pod in “Pending” per via della scarsità di risorse nel cluster, provvederà ad allocare un nuovo nodo adeguato per ospitare il workload in attesa, selezionando la tipologia tra quelle elencate nelle configurazioni del servizio.
Una volta risolto il problema dei pod che rimangono in pending, ne compare uno nuovo: finché vi è scarsità di risorse, Karpenter avvia nuovi nodi. La domanda cruciale è: si tratta di una scarsità reale o solo percepita dal sistema? Questa definizione di risorse minime necessarie ha qualche tipo di correlazione con l’utilizzo di risorse effettive?
In breve: no. Solitamente la definizione di requests viene omessa, in quanto non siamo molto interessati a definire un minimo per avviare l’applicazione. Siamo bensì molto più interessati a definire un limite massimo di risorse che il pod può utilizzare, per evitare di saturare il nodo e inficiare le performance degli altri pod in esecuzione nello stesso worker.
Dalla documentazione di Kubernetes troviamo quindi:
"If you specify a limit for a resource, but do not specify any request, and no admission-time mechanism has applied a default request for that resource, then Kubernetes copies the limit you specified and uses it as the requested value for the resource."
Di conseguenza, un pod con un limit di 2 vCPU e 4 GB di RAM viene schedulato solo se l'intero ammontare di queste risorse è disponibile, poiché, in assenza di requests esplicite, i due valori vengono fatti coincidere.
Capita quindi che vi siano molti pod in esecuzione che non necessitano realmente di tutte le risorse che lo scheduler ritiene debba trovare, ma che per via delle definizioni presente è tenuto a farlo.
Questo nel nostro caso è stata la causa principale della crescita di nodi del cluster (sia aggiunti manualmente nel nodegroup, che aggiunti al volo da Karpenter). L’aggiunta di nuovi pod creava una crescita sproporzionata nei worker necessari al cluster EKS, con una diretto impatto sui costi poiché si andavano ad allocare EC2 aggiuntive, che facevano di conseguenza lievitare i costi.
Gli obiettivi
Per ridurre questi costi e gli sprechi correlati ci siamo quindi posti l’obiettivo di revisionare tutte le risorse richieste dai pod, effettuando un’analisi approfondita delle risorse utilizzate al fine anche di identificare le famiglie di macchine migliori per i worker del cluster, ottimizzando quindi l’utilizzo e i costi selezionando tipologie più adeguate. L’analisi quindi dovrebbe permetterci di avere il numero minore possibile di worker utilizzati, sfruttando al meglio le risorse disponibili.
La soluzione
1. Implementazione e raccolta dati
Per condurre un'analisi approfondita e basata su dati concreti, abbiamo scelto di installare kube-prometheus-stack nei cluster Kubernetes oggetto del nostro studio. Questo stack include componenti essenziali come Prometheus, per la raccolta di metriche dettagliate e continue, e Grafana, per la visualizzazione e l'analisi di tali dati.
Dopo aver completato l'installazione, il sistema è stato lasciato in esecuzione per diverse settimane. Questo periodo di tempo prolungato ci ha permesso di accumulare una quantità significativa e rappresentativa di metriche relative all'utilizzo delle risorse da parte dei pod e dei nodi. Una raccolta dati estesa è stata cruciale per cogliere le variazioni su lunghi periodi, i picchi di carico e i periodi di inattività, fornendo una base solida per l'analisi successiva.
1.1. Analisi delle risorse con Prometheus e Grafana
Una volta raccolti i dati, abbiamo proceduto con l'analisi degli stessi utilizzando le funzionalità offerte da Prometheus e Grafana. Questo processo si è articolato in diverse fasi:
Fase 1 - Identificazione dei pod con richieste inadeguate
Abbiamo utilizzato PromQL (Prometheus Query Language) per interrogare le metriche e identificare i pod che presentavano un divario significativo tra le risorse richieste (requests) e l'effettivo consumo (usage). Query specifiche ci hanno permesso di evidenziare:
- pod con
requestsmolto elevate rispetto al lorousagemedio, indicando una potenziale sovrallocazione; - pod con
usageche superava frequentemente lerequests(e talvolta ilimits), segnalando una sottodimensionamento che poteva portare a problemi di performance o interruzioni.
Fase 2 - Verifica dei pod con risorse errate
Attraverso dashboard personalizzate in Grafana, abbiamo visualizzato l'andamento storico dell'utilizzo di CPU e memoria per i singoli pod e i nodi. Questo ci ha permesso di:
- confermare le anomalie individuate con PromQL;
- visualizzare i pattern di utilizzo nel tempo, identificando se le sovrallocazioni o sottodimensionamenti fossero costanti o legati a specifici eventi.
Fase 3 - Applicazione di LimitRange
Per stabilire valori predefiniti e limiti per le risorse nei namespace, laddove le requests fossero state omesse, abbiamo considerato l'implementazione di LimitRange. Questo strumento di Kubernetes permette di:
- assicurare che tutti i pod abbiano almeno una richiesta di risorsa definita, evitando che Karpenter interpreti i limits come requests portando a sovrallocazioni;
- standardizzare le configurazioni di risorsa, facilitando una gestione più prevedibile del cluster.
Fase 4 - Revisione dei pod con difficoltà di avvio
Abbiamo analizzato i log e le metriche dei pod che mostravano tempi di avvio prolungati o fallimenti ricorrenti (CrashLoopBackOff), spesso a causa di requests di risorse troppo ristrette. L'obiettivo era identificare:
- spike di consumo di risorse durante la fase di avvio che non erano adeguatamente gestiti dalle requests iniziali;
- modificare le requests di questi pod per garantire un avvio più fluido e stabile, senza compromettere l'efficienza complessiva.
Vediamo nel dettaglio le singole operazioni di analisi che sono state effettuate.
1.1.1. Identificazione dei pod con richieste inadeguate e verifica dei pod con risorse errate
Le metriche oggetto di analisi sono state CPU e Memory. Abbiamo quindi identificato all’interno delle nostre istanze Prometheus quali fossero le metriche più adeguate a disposizione. Abbiamo identificato quindi le seguenti metriche:
- node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate
- namespace_cpu:kube_pod_container_resource_requests:sum
- namespace_memory:kube_pod_container_resource_requests:sum
- container_memory_rss
Le prime tre metriche vengono calcolate attraverso delle recording rule specifiche, già disponibili by default nell’installazione di kube-prometheus-stack. Queste regole effettuano un preprocessing avanzato di diverse altre metriche grezze, aggregandole e trasformandole per produrre un valore precalcolato più significativo e immediatamente utilizzabile. Questo approccio migliora l'efficienza e la chiarezza dei dati, fornendo un'indicazione sintetica ma accurata di parametri complessi.
L'ultima metrica, invece, è una metrica nativa. Essa cattura e mostra direttamente la misurazione reale della memoria residente utilizzata da ogni singolo container. A differenza delle metriche derivate, questa offre un'immagine granulare e non elaborata del consumo di risorse a livello di container, fondamentale per un'analisi dettagliata e per identificare eventuali anomalie o inefficienze nello sfruttamento della memoria.
Abbiamo quindi selezionato i namespace che necessitavano di intervento attraverso l’esecuzione di una query per trovare i namespace che contengono pod dove le resources impostate sono sovradimensionate rispetto all’uso reale. Questo non indica necessariamente la presenza di carichi di lavoro inefficienti ('spreconi'), ma serve a orientare l'indagine sulle aree a maggior potenziale di ottimizzazione..
Le query PromQL utilizzate per CPU e RAM sono state le seguenti
RAM
La query seleziona i namespace in cui il rapporto tra l'uso effettivo della RAM (somma di container_memory_rss) e le risorse allocate (requests) è inferiore a 0.5. Un valore così basso indica che viene utilizzata meno della metà della memoria riservata.
CPU
Questa query ha selezionato tutti i namespace dove la somma dell’uso effettivo della CPU di tutti i container diviso la somma delle requests sulla CPU era inferiore a 0.1. Un valore così basso indica un utilizzo molto ridotto della CPU rispetto a quanto riservato, suggerendo una significativa sovrastima delle risorse necessarie e, di conseguenza, un'opportunità di ottimizzazione. Dal punto di vista tecnico la CPU è la risorsa più “scarsa”, ma anche la più utilizzata se un’applicazione è effettivamente in uso. E quindi necessario intervenire prioritariamente.
Una volta identificati i namespace oggetto di intervento, abbiamo analizzato singolarmente i pod di ogni namespace, verificando l’utilizzo effettivo delle risorse.
Nell’installazione di default dello stack di monitoraggio di Prometheus è già presente una dashboard che può aiutare nelle analisi mostrando questi dati:
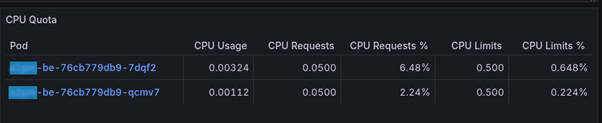
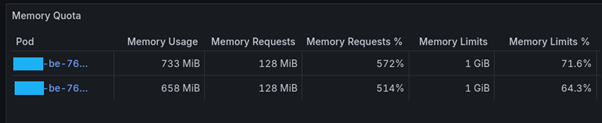
Le metriche riportate in queste due tabelle permettono di identificare un workload che sta utilizzando poche risorse rispetto a quelle riservate (CPU Requests % e Memory Requests %). Se questi valori sono eccessivamente bassi è possibile intervenire regolando i valori impostati per i vari pod.
Nel caso visualizzato per quanto riguarda la CPU le risorse riservate minime (requests) sarebbero abbondanti, ma il valore impostato (CPU Requests) è già molto basso (5% di cpu, o 50m, secondo la sintassi Kubernetes che utilizza “1m” per indicare 0.1% di CPU e 1Mi per un mebibyte, ovvero circa 1MB, di memoria), per cui non ha senso ridurlo oltre senza rischiare di trovarsi con l’impossibilità di gestire degli spike, anche minimi, di CPU.
Per quanto riguarda la memoria invece il valore “Memory Requests %” è molto elevato, quindi significa che il parametro impostato non è sovradimensionato rispetto alle richieste. Questo però indica che è necessario anche effettuare una verifica che il valore di “Memory Requests” non sia però troppo piccolo, altrimenti il rischio è che l’applicazione all’avvio, in caso di nodo carico, non riesca ad allocare tutte le risorse di cui necessita per avviarsi.
Il caso mostrato è quindi già ottimizzato per ridurre gli sprechi di risorse. Inoltre i limiti impostati sembrano essere più che sufficienti per il funzionamento attuale dell’applicazione.
In ogni caso, tramite il selettore di intervalli di tempo di Grafana, è possibile estrarre le metriche relative a un momento passato per verificare la validità delle scoperte effettuate.
1.1.2. Applicazione di LimitRange
Dall’analisi precedente sono emersi molti pod che non avevano alcun valore di Limit e Request impostati. In questo caso si tratta di pod che vengono schedulati secondo la politica di “Best Effort”. Kube-scheduler troverà un posto disponibile in un worker qualsiasi, anche minimo, e vi pianificherà il pod per l’esecuzione. In buona parte dei nostri worker, dove le risorse di cpu e ram riservate non sono mai utilizzate a pieno, questa schedulazione non porterà ad avere troppi problemi. Nel caso però di carico intenso, in periodi critici, i pod potrebbero essere schedulati su nodi che non hanno realmente risorse a disposizione per un’esecuzione ottimale.
Per gestire in modo più efficace le risorse, in questi scenari dove le richieste e i limiti non sono esplicitamente definiti a livello di pod, ci viene in aiuto il LimitRange di Kubernetes.
GLOSSARIO/HIGHLIGHTS
Best Effort
È la differenza critica tra Requests (risorse garantite) e Limits (limite massimo), che è il fulcro tecnico del problema.
LimitRange
È una policy di Kubernetes che può essere applicata a un namespace per imporre vincoli sulle risorse di CPU e memoria. Consente di:
- specificare valori predefiniti di richieste e limiti per i pod, i container e gli oggetti PersistentVolumeClaim nel caso in cui non vengano esplicitamente definiti.
- Imporre limiti minimi e massimi per le richieste e i limiti delle risorse;
- Imporre rapporti di richiesta/limite per una risorsa.
Definizione dalla documentazione ufficiale di Kubernetes
A LimitRange provides constraints that can:
- Enforce minimum and maximum amount of compute resources to a Pod or Container in a namespace.
- Enforce minimum and maximum storage request size for a PersistentVolumeClaim in a namespace.
- Enforce a ratio between request and limit for a resource in a namespace.
- Set default request/limit values for compute resources in a namespace if none are specified.
Da come si può evincere, quidni, l'utilizzo di LimitRange è cruciale per prevenire la schedulazione "Best Effort" non controllata e per garantire che tutti i pod abbiano definizioni di risorse più appropriate, anche se non specificate esplicitamente nei descrittori.
Per default abbiamo scelto di applicare dei limiti per container a livello di namespace. La configurazione applicata di default a tutti i progetti è la seguente:
kind: LimitRange
metadata:
name: default-limits-per-namespace
spec:
limits:
- default: # this section defines default limits
cpu: 500m
memory: 512Mi
defaultRequest: # this section defines default requests
cpu: 50m
memory: 128Mi
type: Container
Con la configurazione defaultRequest e default per type: Container se un container non specifica requests o limits, gli verranno assegnati di default 50m di CPU e 128Mi di memoria come richiesta, e 500m di CPU e 512Mi di memoria come limite. Questo evita che Karpenter interpreti i limits come requests (nel caso non vengano esplicitate le requests), riducendo la sovrallocazione.
Applicando, dunqnue, un LimitRange al namespace, ci si assicura che ogni container abbia un set minimo di risorse richieste. Questo ha diversi vantaggi che qui elenchiamo.
- Prevenzione della sovrallocazione - Se le
requestssono omesse e ilimitssono presenti, Kubernetes userà ilimitscomerequests. Con un LimitRange, è possibile impostare undefaultRequestpiù realistico, evitando che un'applicazione che richiede poche risorse in realtà venga schedulata come se ne richiedesse molte. - Stabilità del sistema - Assicura che i pod ricevano risorse adeguate per l'avvio e il funzionamento, riducendo i
CrashLoopBackOffo tempi di avvio prolungati dovuti a risorse insufficienti, soprattutto in momenti di carico intenso. - Ottimizzazione della schedulazione - Fornendo richieste predefinite, lo scheduler di Kubernetes può prendere decisioni più informate su dove posizionare i pod, migliorando l'utilizzo complessivo dei nodi e riducendo il numero di nodi inattivi.
- Standardizzazione - Aiuta a mantenere una configurazione più consistente tra i vari workload nello stesso namespace, semplificando la gestione e il debugging.
L’implementazione di un limit range è stato quindi fondamentale per poter garantire a tutti risorse per l’esecuzione corretta senza sprechi di risorse.
1.1.3. Ottimizzazione della Tipologia di Istanza EC2
Un'ulteriore area di ottimizzazione ha riguardato la selezione delle istanze EC2 che compongono i nodi del cluster. In base all'analisi dettagliata del consumo di risorse, si è valutato ottimale il cambio da Famiglia C a Famiglia R. Abbiamo, infatti, notato che molti dei nostri carichi di lavoro presentavano un utilizzo di RAM proporzionalmente più elevato rispetto alla CPU. Le istanze della famiglia C (Compute Optimized), precedentemente in uso, sono ottimizzate per carichi intensivi di CPU. Abbiamo quindi proposto di migrare verso le istanze della famiglia R (Memory Optimized), che offrono un rapporto RAM/CPU più favorevole e si adattano meglio ai nostri pattern di utilizzo. Questo cambiamento ha permesso di ospitare più pod per nodo, massimizzando l'utilizzo della memoria disponibile e riducendo il numero complessivo di nodi necessari.
L'insieme di queste azioni mira a raggiungere un cluster con un numero ridotto di nodi, ma con un'elevata densità di pod in esecuzione, sfruttando al meglio le risorse hardware e riducendo significativamente i costi operativi.
I risultati
Siamo riusciti a configurare un cluster altamente ottimizzato, caratterizzato da un numero limitato di nodi worker ma capace di supportare l'esecuzione simultanea di numerosi pod. Questa configurazione è il risultato di un'attenta calibrazione delle risorse, in cui abbiamo deliberatamente privilegiato l'utilizzo della memoria RAM rispetto alla potenza di calcolo della CPU. Tale scelta è stata dettata dalla specifica natura dei carichi di lavoro previsti per questo ambiente, che beneficiano maggiormente di un'ampia disponibilità di RAM per le operazioni di I/O e la gestione dei dati in-memory, piuttosto che di cicli di CPU intensivi. Questo approccio ci ha permesso di massimizzare l'efficienza e la densità dei pod per nodo, mantenendo al contempo bassi i costi infrastrutturali e garantendo un'elevata reattività del sistema. La flessibilità di questa configurazione consente inoltre di adattare dinamicamente le dimensioni del cluster, scalando le risorse in base alle esigenze mutevoli dei nostri servizi e applicazioni.
Inoltre, l'ottimizzazione dell'utilizzo delle risorse ha portato a una significativa riduzione della frequenza degli interventi di Karpenter per lo scaling del cluster. Grazie a una gestione più efficiente e mirata delle risorse, la crescita dei nodi è rimasta contenuta e sotto controllo, evitando espansioni impreviste e dispendiose. Questo approccio ha permesso di mantenere un equilibrio ottimale tra prestazioni e costi, garantendo che il cluster si adatti dinamicamente al carico di lavoro senza sprechi eccessivi.
Raccomandazioni finali
È fondamentale includere richieste di risorse in ogni configurazione di pod su Kubernetes. Tuttavia, è altrettanto cruciale garantire che tali richieste siano attentamente calibrate e sufficienti a coprire il fabbisogno minimo per l'avvio e il funzionamento dei pod. Una stima insufficiente delle risorse potrebbe comportare gravi disservizi, come l'impossibilità dei pod di avviarsi (bloccandosi nello stato "Pending" o "CrashLoopBackOff") o un significativo rallentamento durante la fase di avvio, influenzando negativamente la disponibilità e le prestazioni delle applicazioni. È consigliabile effettuare test approfonditi per determinare i requisiti minimi di CPU e memoria per ciascuna applicazione prima di definire le richieste di risorse nei manifest di Kubernetes.
Ti è piaciuto quanto hai letto? Iscriviti a MISPECIAL, la nostra newsletter, per ricevere altri interessanti contenuti.
Iscriviti a MISPECIAL

